
Distributed Processing¶
This mode assumes that the data set is split into nblocks blocks across computation nodes.
Algorithm Parameters¶
The K-Means clustering algorithm in the distributed processing mode has the following parameters:
Parameter |
Default Value |
Description |
|---|---|---|
|
Not applicable |
The parameter required to initialize the algorithm. Can be:
|
|
|
The floating-point type that the algorithm uses for intermediate computations. Can be |
|
|
Available computation methods for K-Means clustering:
|
|
Not applicable |
The number of clusters. Required to initialize the algorithm. |
|
\(1.0\) |
The weight to be used in distance calculation for binary categorical features. |
|
|
The measure of closeness between points (observations) being clustered. The only distance type supported so far is the Euclidian distance. |
|
|
A flag that enables computation of assignments, that is, assigning cluster indices to respective observations. |
To compute K-Means clustering in the distributed processing mode, use the general schema described in Algorithms as follows:
Step 1 - on Local Nodes¶
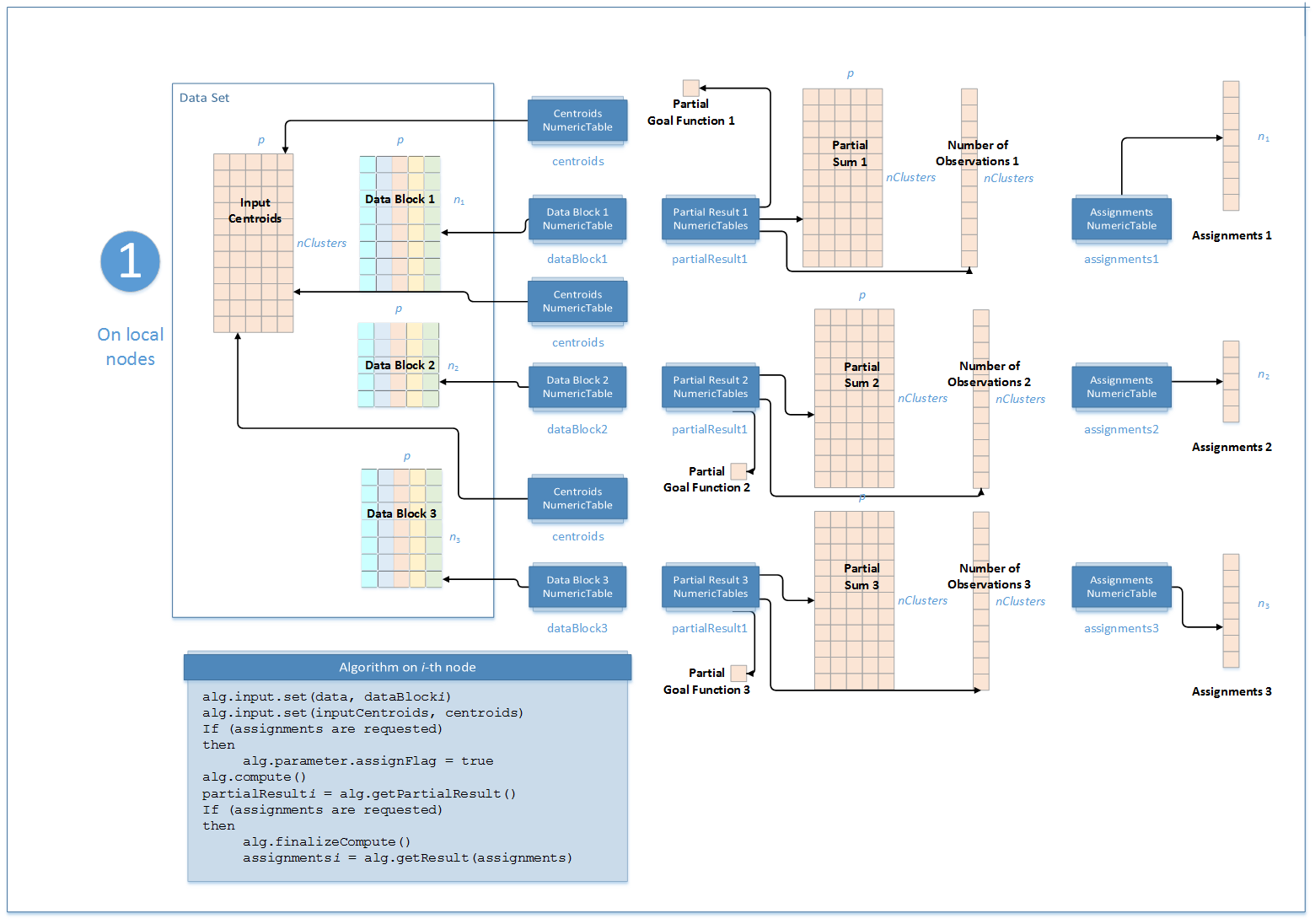
K-Means Computaion: Distributed Processing, Step 1 - on Local Nodes¶
In this step, the K-Means clustering algorithm accepts the input described below.
Pass the Input ID as a parameter to the methods that provide input for your algorithm.
For more details, see Algorithms.
Input ID |
Input |
|---|---|
|
Pointer to the \(n_i \times p\) numeric table that represents the \(i\)-th data block on the local node.
The input can be an object of any class derived from |
|
Pointer to the \(\mathrm{nClusters} \times p\) numeric table with the initial cluster centroids. This input can be an object of any class derived from NumericTable. |
In this step, the K-Means clustering algorithm calculates the partial results and results described below.
Pass the Partial Result ID or Result ID as a parameter to the methods that access the results of your algorithm.
For more details, see Algorithms.
Partial Result ID |
Result |
|---|---|
|
Pointer to the \(\mathrm{nClusters} \times 1\) numeric table that contains the number of observations assigned to the clusters on local node. Note By default, this result is an object of the |
|
Pointer to the \(\mathrm{nClusters} \times p\) numeric table with partial sums of observations assigned to the clusters on the local node. Note By default, this result is an object of the |
|
Pointer to the \(1 \times 1\) numeric table that contains the value of the partial objective function for observations processed on the local node. Note By default, this result is an object of the |
|
Pointer to the \(\mathrm{nClusters} \times 1\) numeric table that contains the value of the Note By default, this result if an object of the |
|
Pointer to the \(\mathrm{nClusters} \times 1\) numeric table that contains the observations of the Note By default, this result if an object of the |
Result ID |
Result |
|---|---|
|
Use when Note By default, this result is an object of the |
Step 2 - on Master Node¶
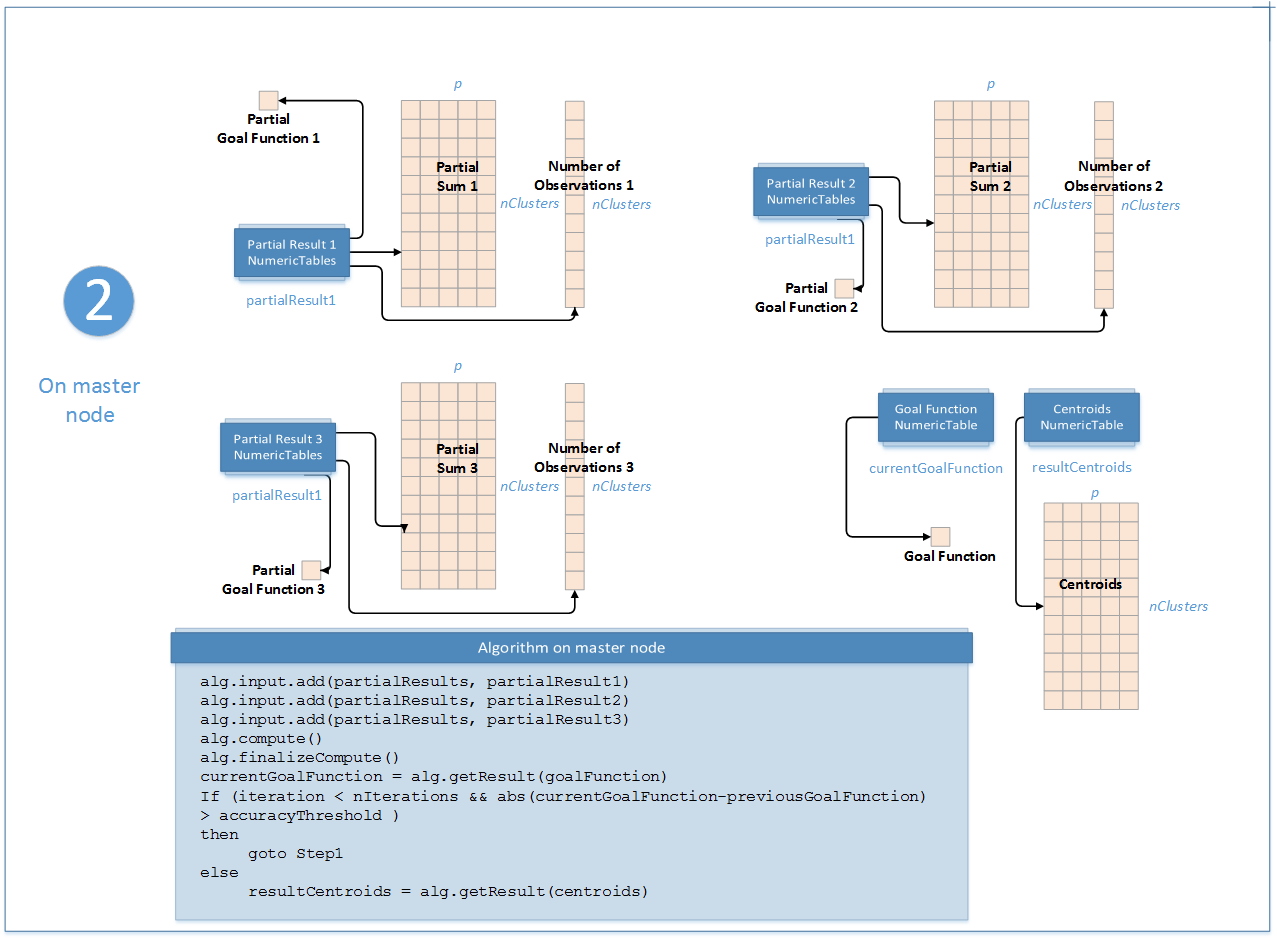
K-Means Computaion: Distributed Processing, Step 2 - on Master Node¶
In this step, the K-Means clustering algorithm accepts the input from each local node described below.
Pass the Input ID as a parameter to the methods that provide input for your algorithm.
For more details, see Algorithms.
Input ID |
Input |
|---|---|
|
A collection that contains results computed in Step 1 on local nodes. |
In this step, the K-Means clustering algorithm calculates the results described below.
Pass the Result ID as a parameter to the methods that access the results of your algorithm.
For more details, see Algorithms.
Result ID |
Result |
|---|---|
|
Pointer to the \(\mathrm{nClusters} \times p\) numeric table with centroids. Note By default, this result is an object of the |
|
Pointer to the \(1 \times 1\) numeric table that contains the value of the objective function. Note By default, this result is an object of the |
Important
The algorithm computes assignments using input centroids.
Therefore, to compute assignments using final computed centroids, after the last call to Step2compute() method on the master node,
on each local node set assignFlag to true and do one additional call to Step1compute() and finalizeCompute() methods.
Always set assignFlag to true and call finalizeCompute() to obtain assignments in each step.
Note
To compute assignments using original inputCentroids on the given node,
you can use K-Means clustering algorithm in the batch processing mode with the subset of the data available on this node.
See Batch Processing for more details.