
Training and Prediction¶
Training and prediction algorithms in Intel® oneAPI Data Analytics Library (oneDAL) include a range of popular machine learning algorithms:
- Decision Forest
- Decision Trees
- Gradient Boosted Trees
- Stump
- Linear and Ridge Regressions
- LASSO and Elastic Net Regressions
- k-Nearest Neighbors (kNN) Classifier
- Implicit Alternating Least Squares
- Logistic Regression
- Naïve Bayes Classifier
- Support Vector Machine Classifier
- Multi-class Classifier
- Boosting
Unlike Analysis algorithms, which are intended to characterize the structure of data sets, machine learning algorithms model the data. Modeling operates in two major stages:
Training, when the algorithm estimates model parameters based on a training data set.
Prediction or decision making, when the algorithm uses the trained model to predict the outcome based on new data.
Training is typically a lot more computationally complex problem than prediction. Therefore, certain end-to-end analytics usage scenarios require that training and prediction phases are done on different devices, the training is done on more powerful devices, while prediction is done on smaller devices. Because smaller devices may have stricter memory footprint requirements, oneDAL separates Training, Prediction, and respective Model in three different class hierarchies to minimize the footprint.
Training Alternative¶
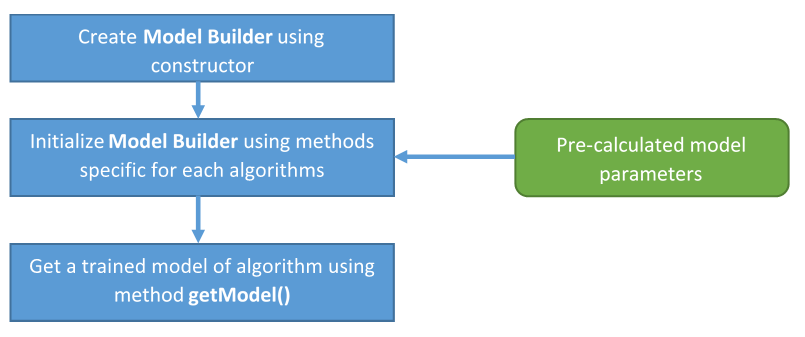
An alternative to training your model with algorithms implemented in oneDAL is to build a trained model from pre-calculated model parameters, for example, coefficients \(\beta\) for Linear Regression. This enables you to use oneDAL only to get predictions based on the model parameters computed elsewhere.
The Model Builder class provides an interface for adding all the necessary parameters and building a trained model ready for the prediction stage.
The following schema illustrates the use of Model Builder class:
The Model Builder class is implemented for the following algorithms: