
Data Management¶
Effective data management is among key constituents of the performance of a data analytics application. For Intel® oneAPI Data Analytics Library, effective data management requires effectively performing the following operations:
Raw data acquisition, filtering, and normalization with data source interfaces.
Data conversion to a numeric representation for numeric tables.
Data streaming from a numeric table to an algorithm.
Depending on the usage model, you may also want to apply compression and decompression to the data you operate on. You can either use compression and decompression embedded into data source interfaces or apply data serialization and deserialization interfaces.
oneDAL provides a set of customizable interfaces to operate on your out-of-memory and in-memory data in different usage scenarios, which include batch processing, online processing, and distributed processing, as well as more complex scenarios, such as a combination of online and distributed processing.
One of key concepts of Data Management in oneDAL is a data set. A data set is a collection of data of a defined structure that characterizes an analyzed and modeled object. Specifically, the object is characterized by a set of attributes (Features), which form a Feature Vector of dimension p. Multiple feature vectors form a set of Observations of size n. oneDAL defines a tabular view of a data set where table rows represent observations and columns represent features.
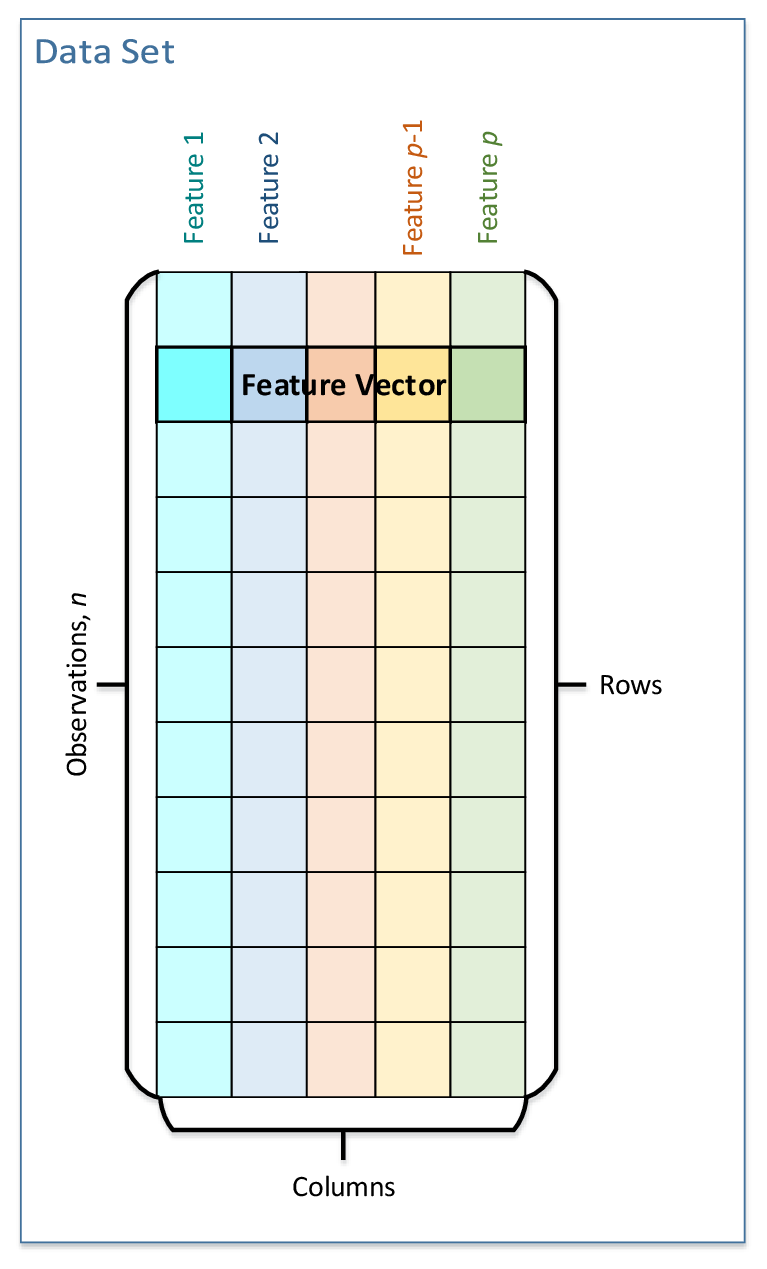
An observation corresponds to a particular measurement of an observed object, and therefore when measurements are done, at distinct moments in time, the set of observations characterizes how the object evolves in time.
It is not a rare situation when only a subset of features can be measured at a given moment. In this case, the non-measured features in the feature vector become blank, or missing. Special statistical techniques enable recovery (emulation) of missing values.
You normally start working with oneDAL by selecting an appropriate data source, which provides an interface for your raw data set. oneDAL data sources support categorical, ordinal, and continuous features. It means that data sources can automatically transform non-numeric categorical and ordinary data into a numeric representation. When the structure of your raw data is more complex or when the default transformation mechanism does not fit your needs, you may customize the data source by implementing a custom derivative class.
Because a data source is typically associated with out-of-memory data, such as files, databases, and so on, streaming out-of-memory data into memory and back is among major functions of a data source. However you can also use a data source to implement an in-memory non-numeric data transformation into a numeric form.
A numeric table is a key interface to operate on numeric in-memory data. oneDAL supports several important cases of a numeric data layout: homogeneous tables, arrays of structures, and structures of arrays, as well as Compressed Sparse Row (CSR) encoding for sparse data.
oneDAL algorithms operate with in-memory numeric data accessed through Numeric table interfaces.